for tweet in tweepy.Cursor(api.search, q='"2020年05月28日" from:@TakumiSoftware').items(10):
if (tweet.text[:2] == 'RT'): continue
print(tweet.user.name)
print(tweet.text)
print('-----------------------------------------------')
for tweet in tweepy.Cursor(api.search_tweets, q='GDP(YoY)').items(10):
print(tweet.text)
としたら10件取得できた
結果が
⠀#EU 1Q 2022
#GDP = 5,4% YoY (5,1% previous)
#GDP = 0,6% QoQ (0,3% previous)
Grammar check: Eurozone GDP in Q1 better than estimated, QoQ +0,6% (estimated +0,3%) vs 0,3% in Q4 2021, YoY +5,4%… https://t.co/T2QYk1MzMT
RT @PatelisAlex: Powering ahead.
Greek real GDP surges 7.0%yoy in Q1 (real, not nominal) https://t.co/pWQqFZB8bi
BNP inom EURO-området bättre än väntat.
European Gross Domestic Product (GDP) YoY 5.4% - https://t.co/R9Ra2BQVGK
Euro area GDP came in stronger than expected for Q1:
+5.4% YoY (est. 5.1%); .6% QoQ (est. .3%).
Output rose .5% Q… https://t.co/U2xUt4c083
RT @Financialjuice1: EUROZONE GDP REVISED YOY ACTUAL 5.4% (FORECAST 5.1%, PREVIOUS 5.1%) $MACRO
EUROZONE GDP REVISED YOY ACTUAL 5.4% (FORECAST 5.1%, PREVIOUS 5.1%) $MACRO

European GDP Growth Rate YoY 3rd Est (Q1)
Actual: 5.4%

Expected: 5.1%
Previous: 4.7%
#EUR
Euro Zone Econ. Stats Released:
GDP (YoY) (Q1)
Actual: 5.4%
Expected: 5.1%
Prior: 5.1%
Better Than Expected

GDP Growth Rate YoY 3rd Est (Q1)
Actual: 5.4%
Expected: 5.1%
Previous: 4.7%
bloomberg = api.user_timeline(screen_name='@business')
# bloomberg
for tweet in bloomberg:
print(tweet.text)
で表示できた
あとは取得したついーとから数字だけ取り出す
for tweet in tweepy.Cursor(api.search_tweets, q='"French oil and gas" from:@business').items(10):
if (tweet.text[:2] == 'RT'): continue
print(tweet.user.name)
print(tweet.text)
print('-----------------------------------------------')

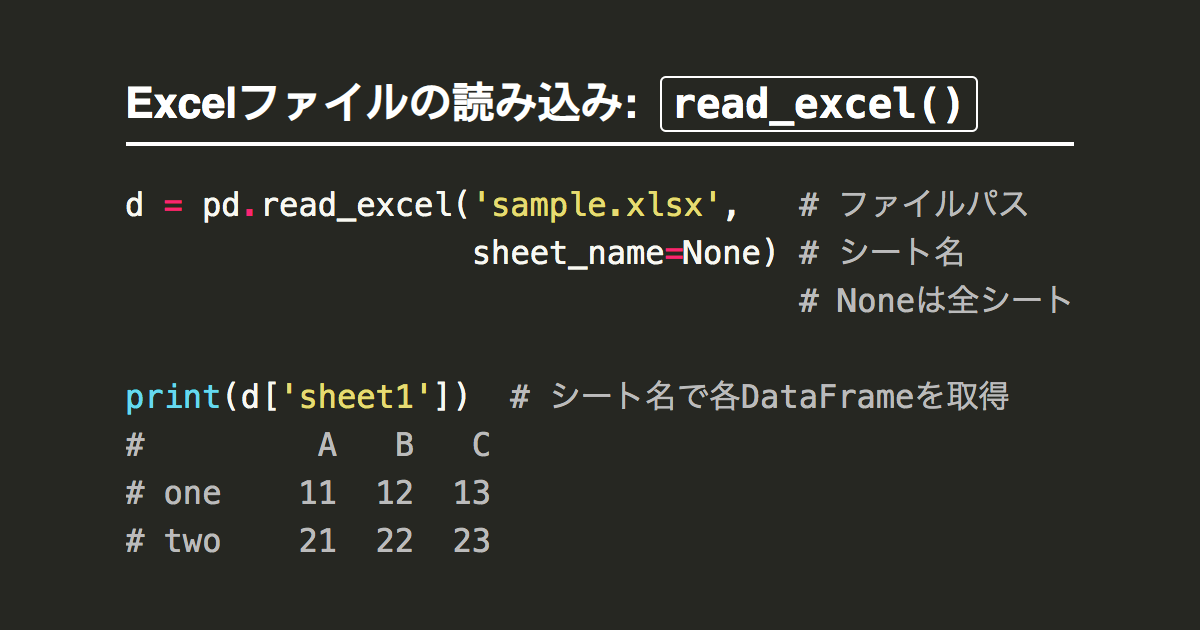



コメント