経済指標の値の取得と計算
とりあえず経済指標の基準値は調べたので
まずは売買するロジックを作成する
経済指標で結果が予測値より悪いなら売り
結果が予想より良いのなら書い
という簡単なロジックを実装する
def dealing_logic(forecast,actual_news):
deal_flag = actual_news - forecast
if deal_flag <0:
print("売り")
else:
print("書い")
まずは簡単に実験
forecast = 962 actual = 853 dealing_logic(forecast,actual)
で売りになったので
次は
マイナスの値で
マイナスの値でも動作するのを確認
次に判定
フラグ変数を用意し
経済指標
債権
株価指数
Vix
といった値で売買判定をする
Vix は警戒とかはマイナスの値を多くすることにする
つまり
Vix は0〜100で
20までは安定しているとみるので
値を0
30で警戒なので-1
40を超えたらパニックなので-2
50 以上はリーマンショッククラスなので-3
とする
このように結果をもとにして
判定するフラグのトータルが+なら書い
マイナスなら売りとする
ダウの下げとかを気にするのではなく
これらをフラグとしておけば市場の数値ではなく
売り買いのみの判定に使える
https://note.nkmk.me/python-pandas-read-excel/
をみた感じだと
read_excel()
で
Pandas でexcel を読み込んでいる
Vix の取得は
import investpy
from datetime import datetime, date, timedelta
from dateutil.relativedelta import relativedelta
import altair as alt
import pandas as pd
today = datetime.today().strftime('%d/%m/%Y')
vix = investpy.get_index_historical_data(index='S&P 500 VIX',country='united states',
from_date='01/01/2010',to_date=today)
vix.loc["2022-06-02"]["High"]
で
25.78
と Hight の値を取得できた
あとは日付の部分を自動で取得したいので
index_date に格納して指定する
index_today = datetime.today().strftime('%Y-%m-%d')
vix.loc[index_today]["High"]
としても同じ
25.78
となったので成功
問題はこれが数値か文字列かによるので
if flag_vix > 50:
print("市場はパニック")
elif flag_vix > 20:
print("市場は正常")
で判定できているので数字になっている
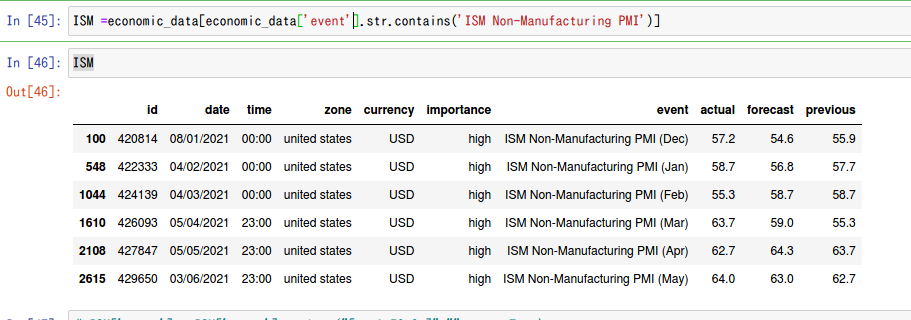
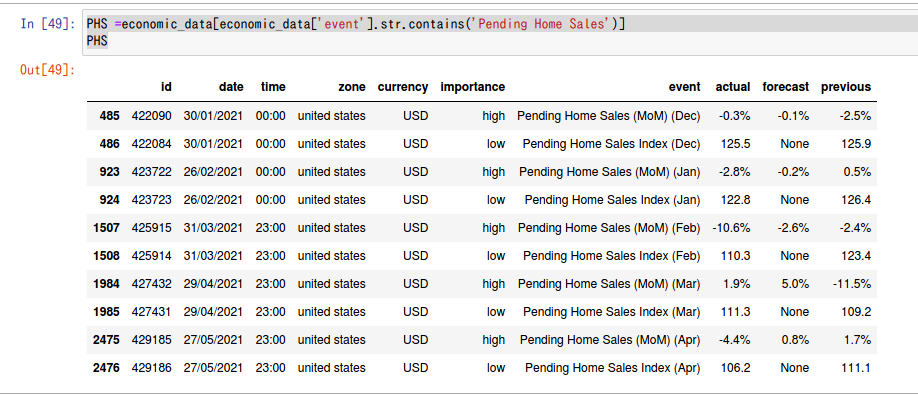
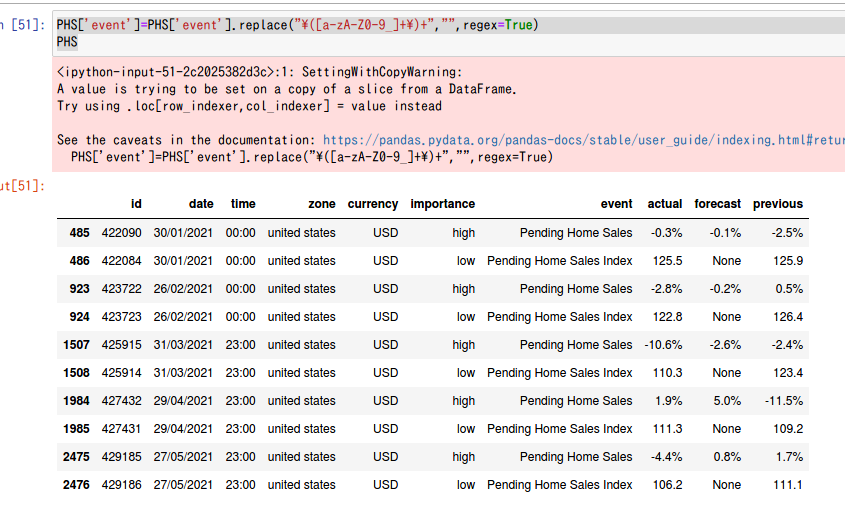
同様に経済指標カレンダーの
Forecast actual previous
の値も取り出してみる
あとtwitter で取得したツイート内容の切り出し
数字以外は削除しないと比較できない
とりあえず broomberg のツイートを取得し
不要な部分を削除し経済指標の数値のみにする
https://teratail.com/questions/266272
によれば
特定ユーザの特定キーワード検索が可能
for tweet in tweepy.Cursor(api.search, q='"2020年05月28日" from:@TakumiSoftware').items(10):
if (tweet.text[:2] == 'RT'): continue
print(tweet.user.name)
print(tweet.text)
print('-----------------------------------------------')
しかしエラーになる
api.search_tweets(q='"RBA Rate Statemen"', lang='ja', result_type='recent',count=12)
もだめ
api.search_tweets(q='"#経済指標"', lang='ja', result_type='recent',count=12)
は動作する
ツイート取得したあとはテキストから数字のみ取り出せればいいので
これを先にやる
for tweet in tweepy.Cursor(api.search_tweets, q='GDP(YoY)').items(10): print(tweet.text)
としたら10件取得できた
結果が
⠀#EU 1Q 2022 #GDP = 5,4% YoY (5,1% previous) #GDP = 0,6% QoQ (0,3% previous) Grammar check: Eurozone GDP in Q1 better than estimated, QoQ +0,6% (estimated +0,3%) vs 0,3% in Q4 2021, YoY +5,4%… https://t.co/T2QYk1MzMT RT @PatelisAlex: Powering ahead. Greek real GDP surges 7.0%yoy in Q1 (real, not nominal) https://t.co/pWQqFZB8bi BNP inom EURO-området bättre än väntat. European Gross Domestic Product (GDP) YoY 5.4% - https://t.co/R9Ra2BQVGK Euro area GDP came in stronger than expected for Q1: +5.4% YoY (est. 5.1%); .6% QoQ (est. .3%). Output rose .5% Q… https://t.co/U2xUt4c083 RT @Financialjuice1: EUROZONE GDP REVISED YOY ACTUAL 5.4% (FORECAST 5.1%, PREVIOUS 5.1%) $MACRO EUROZONE GDP REVISED YOY ACTUAL 5.4% (FORECAST 5.1%, PREVIOUS 5.1%) $MACRO  European GDP Growth Rate YoY 3rd Est (Q1) Actual: 5.4%  Expected: 5.1% Previous: 4.7% #EUR Euro Zone Econ. Stats Released: GDP (YoY) (Q1) Actual: 5.4% Expected: 5.1% Prior: 5.1% Better Than Expected  GDP Growth Rate YoY 3rd Est (Q1) Actual: 5.4% Expected: 5.1% Previous: 4.7% https://t.co/p0AAzoJmBh
なので
ほぼ取得したい内容がある
あとはここから数値のみ取り出して比較できるようにすr
https://docs.tweepy.org/en/stable/client.html#tweepy.Client.search_recent_tweets
のリファレンスを見た感じだと
since_id を指定すればユーザ指定ができそう
なので bloomberg のid を調べる
34713362
がid
あとはこれを指定してできるかどうか
screen_name だと
@business
なので
bloomberg = api.user_timeline(screen_name='@business') # bloomberg for tweet in bloomberg: print(tweet.text)
で表示できた
あとは取得したついーとから数字だけ取り出す
for tweet in tweepy.Cursor(api.search_tweets, q='"French oil and gas" from:@business').items(10):
if (tweet.text[:2] == 'RT'): continue
print(tweet.user.name)
print(tweet.text)
print('-----------------------------------------------')
としたら特定のアカウントで検索もできた
あとはここから数値の抜き取り
https://teratail.com/questions/266272
を参考に特定ユーザツイート検索ができた
marketnews = api.user_timeline(screen_name='@Financialjuice1') # bloomberg for tweet in marketnews: print(tweet.text)
で経済指標の最も早いニュースを英語で取得
marketnews =list(marketnews) marketnews_data = [] for tweet in marketnews: marketnews_data.append(tweet.text) print(marketnews_data[9])
で経済指標発表時のツイート取得
次にこのツイートの中身を数字だけにする
を参考に
Re.sub()
を使い
marketnews_data[3]
を数値だけにする
actual = re.sub(r"\D","",marketnews_data[3]) actual
だと
'025'
となるので
少数だけにしたい
以前、経済指標で数値以外を削除した方法を使う
を参考に
actual = re.sub(r"[^0-9.-]","",marketnews_data[3]) actual
としたが
'.0.25.'
となる
とりあえずリストにすれば正規表現で抜き出しはできるので
あとは処理を調べる
actual = re.sub(r"[^0-9.-]|.$","",marketnews_data[3])
というように
| で条件を追加して
.$ というように末尾が. であるものを削除
ただし最初の . が消せない
また
HONG KONG CPI MOM NSA ACTUAL -0.20% (FORECAST -, PREVIOUS -0.20%) $MACRO
を削除してみると
actual2 = re.sub(r"[^0-9.-]|.$","",marketnews_data[2]) actual2
の結果は
'-0.20--0.20'
となるので
少数を条件式に組み込んだ方がいいかもしれない
"ECB'S DE GUINDOS: EURO-ZONE INFLATION TO STAY ABOVE 8% IN COMING MONTHS."
を処理すると
-8 になる
を参考に小数点と不等号を含む数値のみ抽出する正規表現にする
しかし
[+-]?(?:\d*\.)?\d+(?:(?<!(\.\d+))\.\d*)?
だとエラ〜になる
actual2 = re.sub(r"[^\d.]|.$","",marketnews_data[2]) print(actual2)
にしたら
8
となった
Python の正規表現で . (ドット) を含む数値のみを抽出したい
を参考にした
ただしこれだと複数の数値を1つにしてしまうので
区切る必要がある
findall()
で試したが
actual2 = re.findall(r"\d+",marketnews_data[1]) print(actual2)
とすると
['53', '1', '52', '4', '53', '1']
となって小数点で区切ってしまう
を参考に
actual2 = re.findall("\d+\.\d+",marketnews_data[1])
print(actual2[0])
としたら
53.1
が抽出できた
actual2 = re.findall("[-+]?\d*\.\d+|\d+",marketnews_data[1])
print(actual2)
とすることでマイナスの数値にも対応できた
しかし文字列なので
print(actual2+1)
としたらエラ〜となった
変換すればできそうだが小数点なので
Float になる
Vix を抽出した時
flag_vix の値は少数で比較もできた
flag_vix +1
としても演算し
+1 されている
【Python】型を確認・判定する(type関数、isinstance関数)
を参考に
type(flag_vix)
でデータ型を確認したら
numpy.float64
となった
なので float へ変換してみる
[解決!Python]文字列と数値を変換するには(int/float/str/bin/oct/hex関数)
を参考に
float(actual2)
としたがエラ〜
type(actual2)
で調べたら list だった
を参考に
リスト内のアイテムを Python で numpy.float_() 関数を使用して Float に変換する
import numpy as np actual2_float = np.float_(actual2)
で
print(actual2_float+1)
とすれば計算ができるようになった